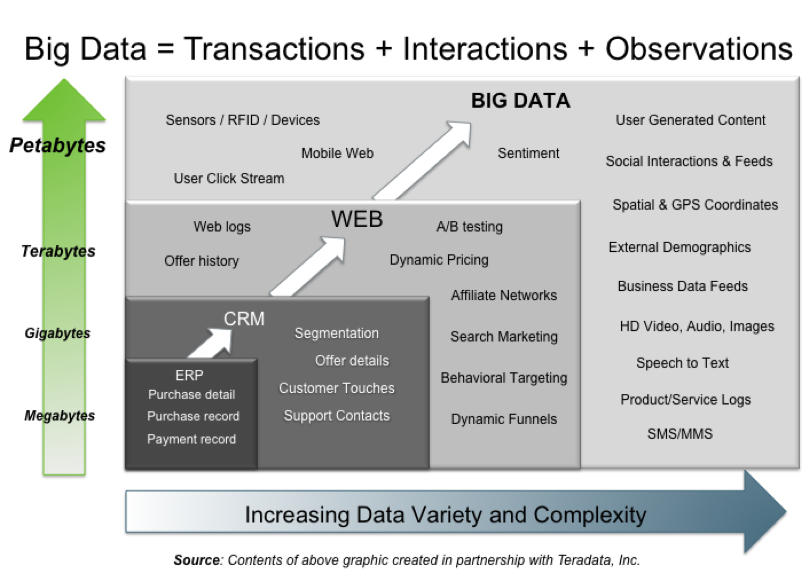
What Exactly is Big Data?
You’ve been to conferences and hear the phrase thrown around quite a bit lately, or you see the buzzword emerging at Inbound.org, but do you really “get” what the phrase big data refers to?
Allow me to give you my interpretation: On an ecommerce website, I like to track backend ERP transaction data, CRM (operations) data, and web analytics. The latter being the most important to my SEO decision-making process – until now.
Until now, I mainly analyzed keyword ranking, sales, cost per sale, cost per click, bounce rates, keywords that resulted in sales from a natural search, attributes of products used in site search that resulted in a sale, abandon rates, click-through rates, basically you name it, I want to track it.
With all of these different data sets, pulled from ERP, CRM, Google Analytics (or other analytics suite), pulled from the shopping cart, pulled from 3rd party tools, pulled from cross-publisher campaign tracking tools and more, it becomes virtually impossible to use every piece of data efficiently with today’s limited technology.
That is, unless your name is @seochick and happen to be an Excel Goddess who looks at numbers in a way that would confuse even the beautiful mind of John Nash.
Enter Big Data Solutions
Imagine being able to take data from various software, web applications, analytics, and history and pipe it all into one system. Here’s an example diagram from Hortonworks:
Now take all that great “stuff” and output it into something useful, something that works automatically while you sleep. For example, take 2,000 products in an online store, each with 20 different attributes (color, size, features, manufacturer, brand, etc) and imagine manually creating a page for each attribute with products that are associated to that attribute, like the color black.
That’s over 40,000 pages!
To clarify, that’s 40,000 presumptuous pages and one heck of a lot of duplicate content (can you say “Google Panda Issue”? I knew you could).
Instead, let’s let the big data solution do some math. What if, for example again, over the last year 70% of buyers chose a product with 1 or more similar attributes and your software could spit out static HTML pages focused ONLY on the products that share that attribute. What could that do for sales?
Inject in some SEO best practices, such as SEO-friendly URLs, optimized HTML titles, meta descriptions, and headings, and your long tail SEO strategy has just been introduced to digital steroids.
Before you ask, no, we’re not talking about site search, which typically renders dynamic URLs and is rarely accurate.
The Inside Scoop
Last week we had the honor of speaking with the geniuses behind the technology that created the big data page above: BloomReach. We spoke with Joelle Kaufman, Head of Marketing at BloomReach, about this innovative new solution that identifies and creates static (optimized) category pages based on big data, such as purchase history, interest data, conversion data, and even external data sources that are then assessed for quality and reviewed by experts prior to launching. These pages are continuously analyzed for visitor happiness (visit duration, clicks, hovers, conversion) and optimized for quality.
Here’s the video from that interview – trust us, you don’t want to miss this behind the curtain preview of big data in action!
BloomReach Highlights
I’d never pitched long tail SEO technology unless I had found one that I actually believe in; one that only works within a website – with no external connections and no system manipulation. Rarely will you find any software featured at here that I haven’t personally tested or seen proof that it does it’s job while following Google Webmaster Guidelines.
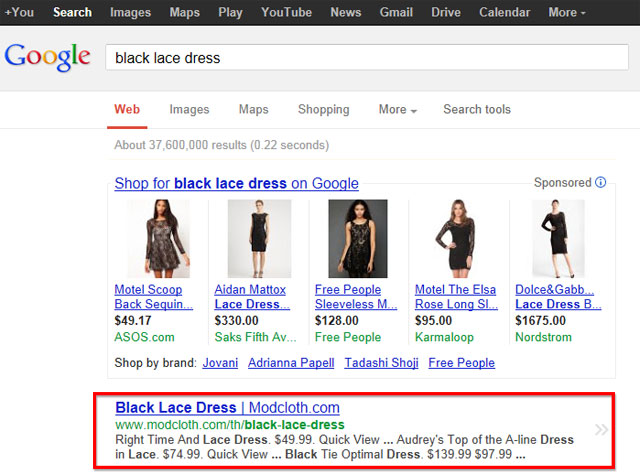
The below example was the proof I needed.
What you see in the Google search results is a page created out of structured concepts identified by BloomSearch – pages that are reviewed prior to publication by experts AND continuously monitored for content freshness and quality. BloomSearch retires any page that falls below a quality threshold. It can’t be “gamed” because the results are real products that match the consumer’s intent – lowering bounce rates and providing positive user experiences.
Even if a page did render low conversion rates and high bounce rates, the system is intelligent enough to remove the page algorithmically.
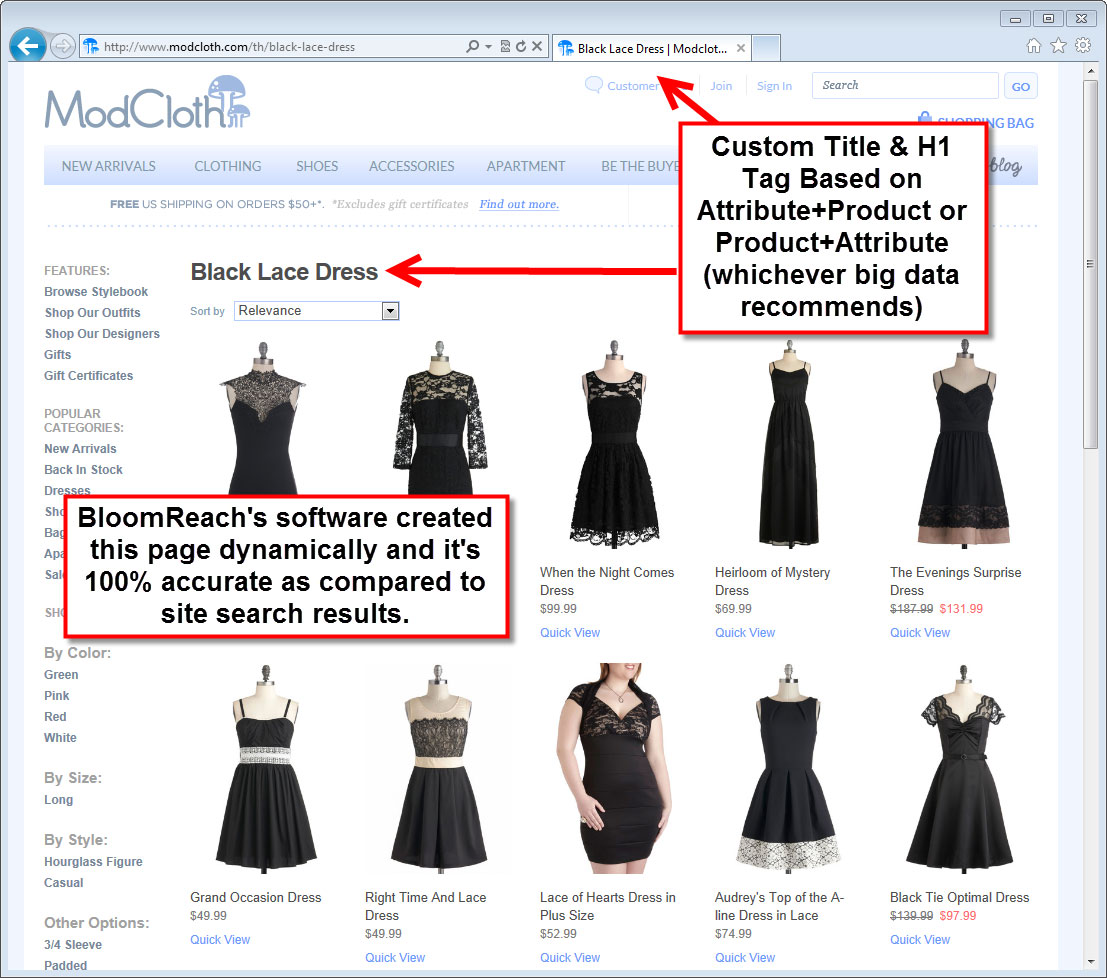
The image below shows the actual page created by the software and identifies the title and heading (h1 tag), both SEO focal points. What you don’t see is the custom meta description or the RDFa code which may even render Rich Snippets in Google results; but both are there, I checked for them myself.
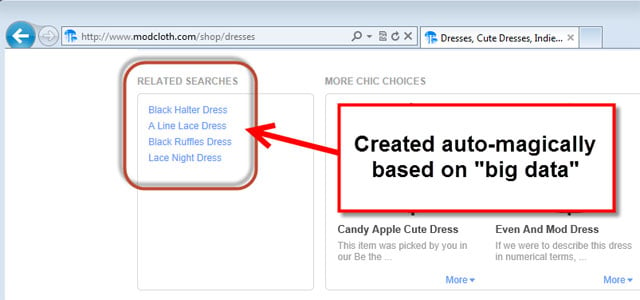
Lastly, here is a screenshot of the “magic widget” that gets inserted into your cart software.
The widget contains “Related Products” links that are never the same for each page (preventing omission by being identified as a common navigation block or region). After all, Googlebot and Bingbot need to crawl URLs to access the dynamic pages, else they become orphaned and inaccessible to web crawlers.
Among it’s ranking signals, Google uses links and co-citations, originally measured by something Larry Page called PageRank. Being able to navigate to core pages on the website is instrumental to the success of those core pages appearing within Google (and Bing/Yahoo!) search engine results.
Looks Expensive, Right?
As it turns out, BloomReach is actually a performance-based solution at the moment, meaning many advertisers can start receiving new revenue from new pages on a profit-share model. There are of course minimum requirements and other considerations. For example, if you sell less than ten $19.95 products, this software probably isn’t for you.
Are you using a big data solution? If so, which one, and how is it working for you? Please share your feedback in the comments below.





